
Understanding the world of spontaneous language modeling in speech recognition
March 1, 2023

This blog is by Valluri Saikiran, Senior Speech Recognition Engineer & Emma O’Neill, Computational Linguist
Spontaneous speech language modeling involves the creation of language models (LM) that can accurately recognize, process, and analyze the complexities of spontaneous human speech in real time, with minimal contextual information.
Language modeling for spontaneous speech is challenging, as spontaneous speech can be unpredictable and inconsistent, and, often, not limited to a single domain. These challenges are magnified further when it comes to kids’ speech.
At SoapBox Labs, we’ve been championing the rise of spontaneous LMs and using them since their earliest iterations in the development of our voice engine for kids.
This blog covers:
- What are spontaneous LMs?
- Examples and applications of spontaneous language modeling
- Challenges in spontaneous language modeling
- Addressing the challenges
- Evaluation metrics
What are spontaneous language models?
Language models are a vital component of speech recognition systems since they allow us to determine the most likely sequence of words being spoken.
For example, the sentence “I like to read” is more probable than “I like to reed” even though both sentences sound the same.
In this regard, a language model has to be suited to the type of speech we want the recogniser to handle.
Modeling spontaneous speech, therefore, involves supporting language that can cover a wide range of topics, sentence constructions, and disfluencies that can often occur.
Compare this with the arguably easier task of modeling read speech, where we can expect sentences to be grammatical, words to be well-formed, and the speaker to stay on-topic.
The custom language models used in our SoapBox Fluency solution are an example of how models that are primarily designed for read speech can also be expanded to account for insertions of unexpected words and sentences.
Fluency is built to automate oral reading fluency assessments. Given a predefined passage, it analyzes the audio file of a child and compares it to the passage itself, and generates a set of related oral-reading data points (omissions, self-corrections, pauses, etc.). In other words, our custom language models used in Fluency know what the child is expected to say and make predictions on what the child actually said if they go off script.
Catering to the spontaneous off-script speech of children, however, is a different challenge, requiring the development of custom LMs that can also handle a wide variation of speech styles.
SoapBox’s custom spontaneous language models can be robustly deployed to allow a child to freely articulate their response to a prompt or question. These models surface not just an accurate transcription of spoken words but also hesitations and disfluencies, valuable data for clients of our voice engine looking to track and assess language competency.
Examples and applications of spontaneous speech language modeling
There are many everyday applications for spontaneous speech language modeling, such as interacting with a voice-activated digital assistant or using voice dictation software to transcribe anything from a casual conversation between friends to a polished speech by a prominent speaker.
At SoapBox, there are applications of spontaneous language modeling across all of our education use cases including literacy and language learning. For example:
- Language assessment: A child responds to a prompt such as: “Tell me about your last vacation.”
- Reading comprehension: A child responds to a question such as: “Why was Jose sad?” or “What did you learn about the greenhouse effect in this story?”
- Retell: “What happened when Casey went into the fruit section?”
- Conversation: “Leave a voice message for your friend to explain why you will be late for your playdate.”
What are the challenges of spontaneous speech language modeling?
The key challenge of spontaneous language modeling is the vast variety of vocabulary and sentence formations a speaker could liberally use, including their mispronunciations and disfluencies. The speech recognition system must precisely decode different word combinations or articulations, which are often outside of the expected domain.
Children’s speech is even more challenging
Since SoapBox works with children’s speech, we must also account for kids’ unique speech and language patterns.
When a child is prompted to think on the spot, their responses can often be off topic, ungrammatical, and include more mispronunciations and disfluencies than that of an adult’s.
To pick up the above example, this is how a child might respond to an open-ended question in an English language learning activity:

Addressing the challenges of spontaneous speech LMs
At SoapBox, we’re building spontaneous language models for domain-specific responses to predefined questions or prompts such as, “Describe what happened to Diane in the passage you just read.”
We also need to be able to accurately transcribe the spontaneous interjections and disfluencies that a child might exhibit while reading a fluency passage. For example, what are they saying when they go off-script?
Building these spontaneous custom LMs requires large quantities of relevant, targeted data of children engaging in these particular language patterns and behaviors.
The training data should primarily satisfy two requirements:
- Coverage: The training data should cover all combinations of words, disfluencies, or hesitation sounds that could occur in our client’s use cases.
- Domain relevant: The training data should also include the prompt text or the passage the child was asked to read, as well as text contents that are closely related to the prompt’s domain.
At SoapBox, we use our proprietary datasets of children’s speech to address the challenges of modeling spontaneous speech in all contexts. We analyze children’s speaking patterns to craft custom language models that can accurately predict the way children commonly behave while using the literacy and language learning tools of our clients, for example, thus creating speech systems that accurately model and predict children’s reading and speaking behaviors in these scenarios.
Evaluation metrics for spontaneous speech language modeling
Word error rate (WER) is the most important metric for evaluating speech recognition systems and, thus, the language model component.
To calculate WER, the reference transcripts (usually, human annotated data) of the evaluation dataset and the speech recognition output transcriptions are aligned and compared for word mismatches.
Then, the final WER is calculated as the ratio of the total number of word mismatch errors and the total number of words in the reference transcripts of the evaluation dataset.
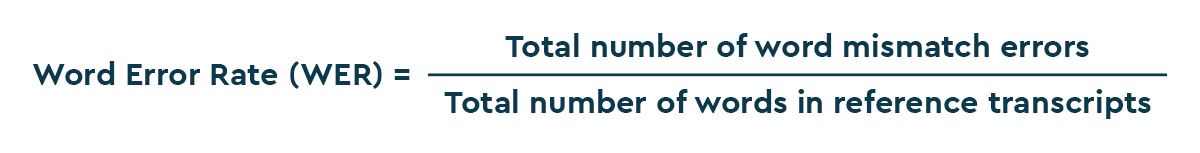
Supplied by our clients, we have on-field test audio recordings that contain children’s responses to various prompts or tasks.
We use this test data to evaluate our spontaneous LMs based on the WER of our ASR outputs compared to the reference annotations of the on-field test data.
We also evaluate our language models directly using a perplexity metric. Perplexity tells us how predictable a test sentence or passage is given a specific language model (how perplexed the model is by such a sequence). A low perplexity value means the model does a good job of capturing the language style it is being tested on.
Future directions for spontaneous language modeling
SoapBox will continue to apply our spontaneous language modeling capabilities to our large proprietary data set of child speech, and continue to deepen our understanding of kids’ speech and behaviors at every stage of the literacy journey, for example, from phonological awareness through to fluency and comprehension.
By continuing to improve the robustness of our spontaneous language models, SoapBox will ensure that our voice engine provides even more rich and granular feedback to educators — and parents — as they guide children on language, literacy, and other learning journeys powered by SoapBox solutions.
Learn more about SoapBox
For more blogs from our Engineering, Speech Technology, and Product teams on how SoapBox builds our speech recognition for kids, visit our Medium page.
