
Self-corrections: Introducing a new feature for automated oral reading assessments
September 30, 2022

This blog is by Brenda McGuirk, Head of Education Product
One of an educator’s many important responsibilities is monitoring the reading level and progress of every student in their classroom.
As students advance through the literacy journey, from learning to read to reading to learn, oral reading fluency data becomes crucial to measuring independent reading mastery, and identifying struggling and underachieving readers who require intervention and support.
SoapBox Fluency — our speech technology solution for reading assessments — is designed to return deep, rich data points to teachers to help identify a student’s reading level and progress, support differentiated instruction, and inform intervention and lesson planning.
SoapBox Fluency currently returns the following data points in near real time to teacher dashboards, helping them to more easily track student progress and identify where a student may be struggling:
- Transcription of the reading
- Words read
- Word confidence (how confident our voice engine is that a specific word was said)
- Phoneme confidence (how confident our voice engine is that a specific phoneme was said)
- Number of words correct
- Time stamps
- Reading errors (substitutions, omissions, insertions, hesitations, and repetitions)
Automatically receiving these data points frees up valuable teaching time and provides teachers and schools consistent and objective longitudinal data for every student.
SoapBox works closely with our literacy and language learning partners to add new high-value features to our speech technology solutions.
Our newest feature for our Fluency solution is “self-corrections.”
Below, we explain what self-corrections are, the role they play in a child’s reading process, and how they are analyzed by our speech technology.
What is a self-correction in reading?
Along with accuracy rate and errors, self-corrections are a key metric scored in running records and observed oral reading fluency (ORF) assessments.
Definitions of “self-corrections” vary. For example, for DIBELS, a widely-adopted system for assessing kids’ literacy skills, a self-correction is when “a student makes an error but corrects it within three seconds.”
Example of a child self-correcting
A typical scenario of self-correcting is when a child gets the beginning of a word correct, the remainder incorrect, immediately notices their mistake and self-corrects it.
For example, when reading a passage, a child pronounces the word “Patch” as “Pat” then self-corrects to “Patch”:
“Look what the dog Pat Patch found.”

Why self-correction is important
In an observed ORF assessment, a teacher is monitoring a student’s comprehension, reading level, and reading process and marking their self-corrections.
Typically, self-corrections are not counted as reading errors but as a positive sign that a child is self-monitoring, taking ownership of their reading, and comprehending the reading passage.
A recent study found that self-correcting behavior “significantly and positively predicted early reading progress for struggling readers.”
However, pausing and self-correcting frequently can also raise concerns about a child’s potential for accurate reading and may indicate fluency problems that require teacher intervention.
In intervention programs, self-correction metrics are important markers of the need for additional support and are sometimes treated as errors.
Analyzing self-corrections with speech technology
With the development of our new self-corrections feature, SoapBox offers education and edtech companies the flexibility to choose if and how they wish to surface data on self-corrections to teachers.
Optimizing our self-corrections feature
Here’s how SoapBox optimized our self-corrections feature for use in the classroom.
How our voice engine identifies a self-correction
Based on extensive research and customer validation, we have defined a self-correction as an inserted word immediately followed by a word that is flagged as correct. Within this broad definition, we identified three key use cases (which we explore in detail later in this post).
Additionally, two or more consecutive words in a child’s speech must be linked together in a meaningful way to count as a self-correction, rather than simply as a mistake followed by a correct word.
How much time we allow between a mistake and a self-correction
As mentioned above, a variety of different standards are applied to constitute a self-correction (e.g., the DIBELS system allows three seconds or less). To ensure flexibility, SoapBox customers can choose the pause time that works best for their tool or product depending, for example, on whether their tool is used for practice or as part of a formal assessment.
As one of our customers explained during our research conversations:
“I’m happy to see that SoapBox will offer self-corrections as a new data point. Very often, a child will struggle to decode, getting the first part of the word correct, struggling on the second part, and then self-correcting. This is probably the most common reading error.”
Our new set of self-corrections data points
We’ve added a new set of data points to the JSON response produced by our voice engine (as below) to accommodate self-corrections. These new points surface details that allow educators to correctly identify the self-corrected words and ignore those errors, if required.
The new data points that belong to the word-level structure are:
- time_since_previous: Indicates how far (in seconds) a word is from the previous one
- self_correction: Flags if a correct word in the output is the self-correction of previous words
- reparandums: Contains the list of word indexes to identify the insertion errors that are corrected by a self-correction word

3 use cases for self-corrections
Our self-corrections feature supports three key use cases. They have been robustly validated with customers to ensure they address the majority of commonly made self-corrections in ORF.
1. Repetition
This use case improves our current repetition feature to account for self-corrections.
Our voice engine now examines a word confidence score and duration to differentiate a self-correction from an insertion. It looks for a pattern where a word is said with low confidence or high duration and is then followed immediately by a high-confidence or shorter duration version of the word.
If the repeated word has 10% or higher confidence than the first time it was said, the second word is considered a self-correction of the first word.
If the repeated word has 30%+ shorter duration than the first time it was said, the second word is considered a self-correction of the first word, even if the confidence is similar for both words.
This use case accounts for situations where a child takes a long time to utter a word (e.g., elongating the letters in a word, likely as an attempt to decode [sound out] the word without fully stopping speaking) and then says the word again more fluently.
Example:
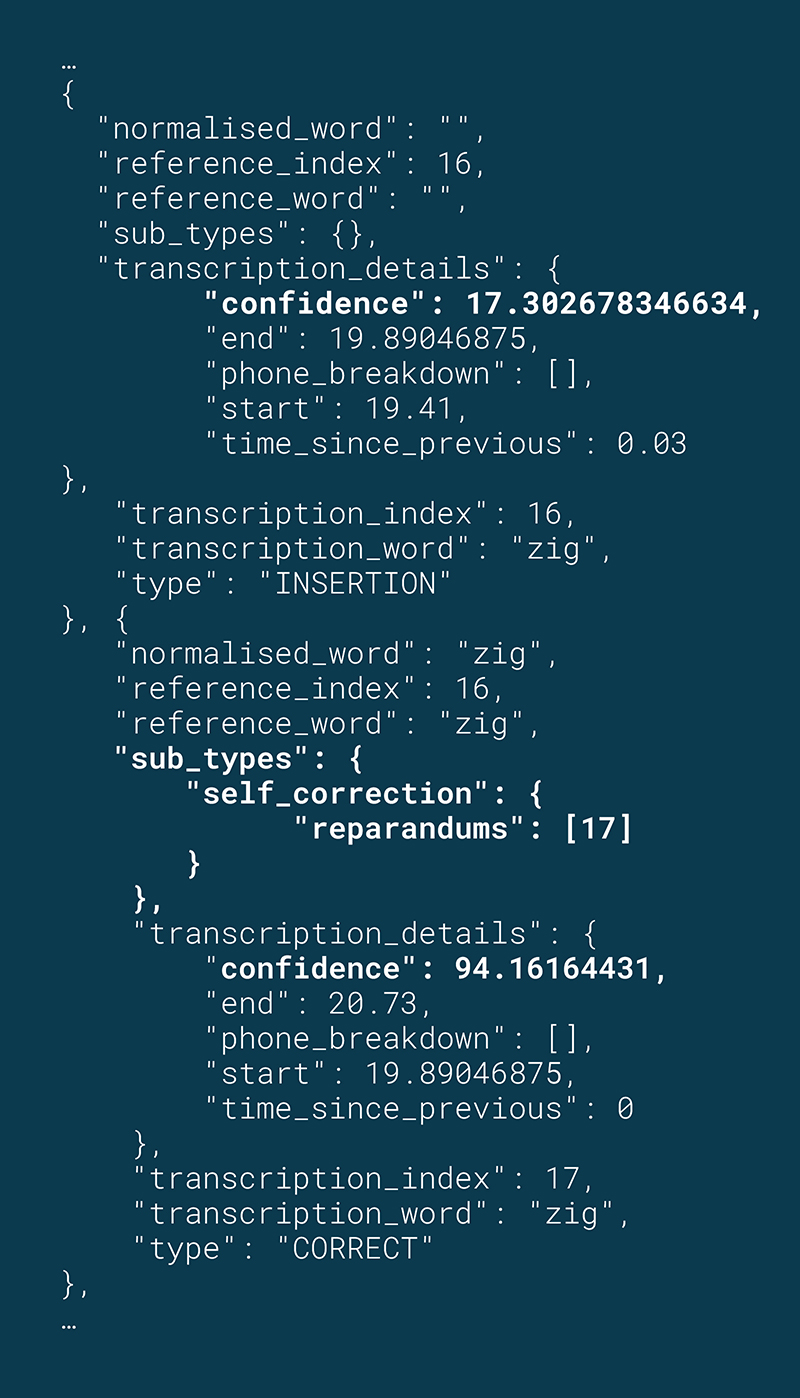
Higher confidence repeated word: A student is reading a passage. When they get to the word zig, they decode it and have poor articulation on the final part of the word. The student then repeats “zig” correctly.

JSON excerpt:
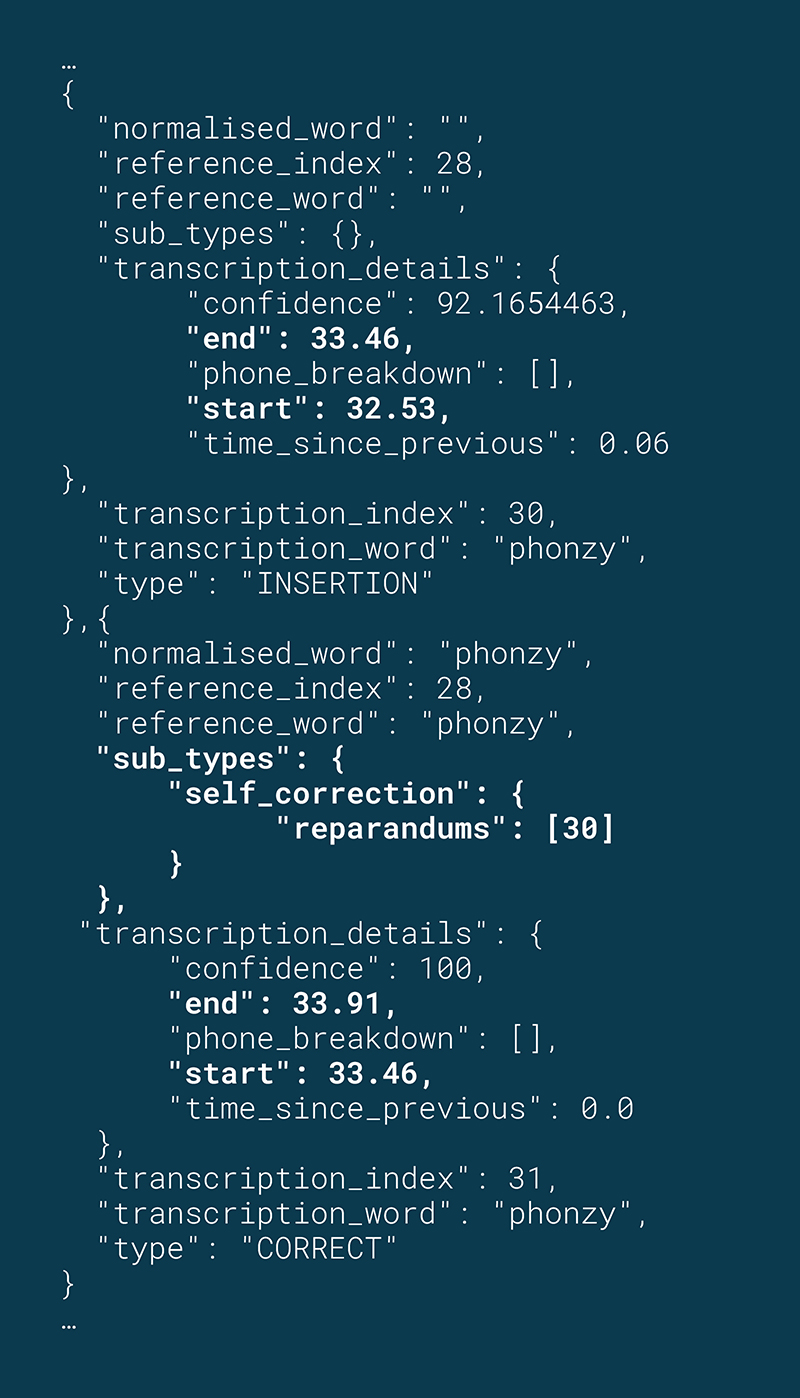
Shorter duration repeated word: The student continues reading. When they get to the word Phonzy, they slowly sound it out. Then they repeat “Phonzy” faster and more fluently.

JSON excerpt:
2. Phonetically similar words
For this use case, the SoapBox voice engine looks for a pattern where a student reads a word incorrectly, but the incorrect word and correct word are phonetically similar, and the student self-corrects to the correct word.
Example:
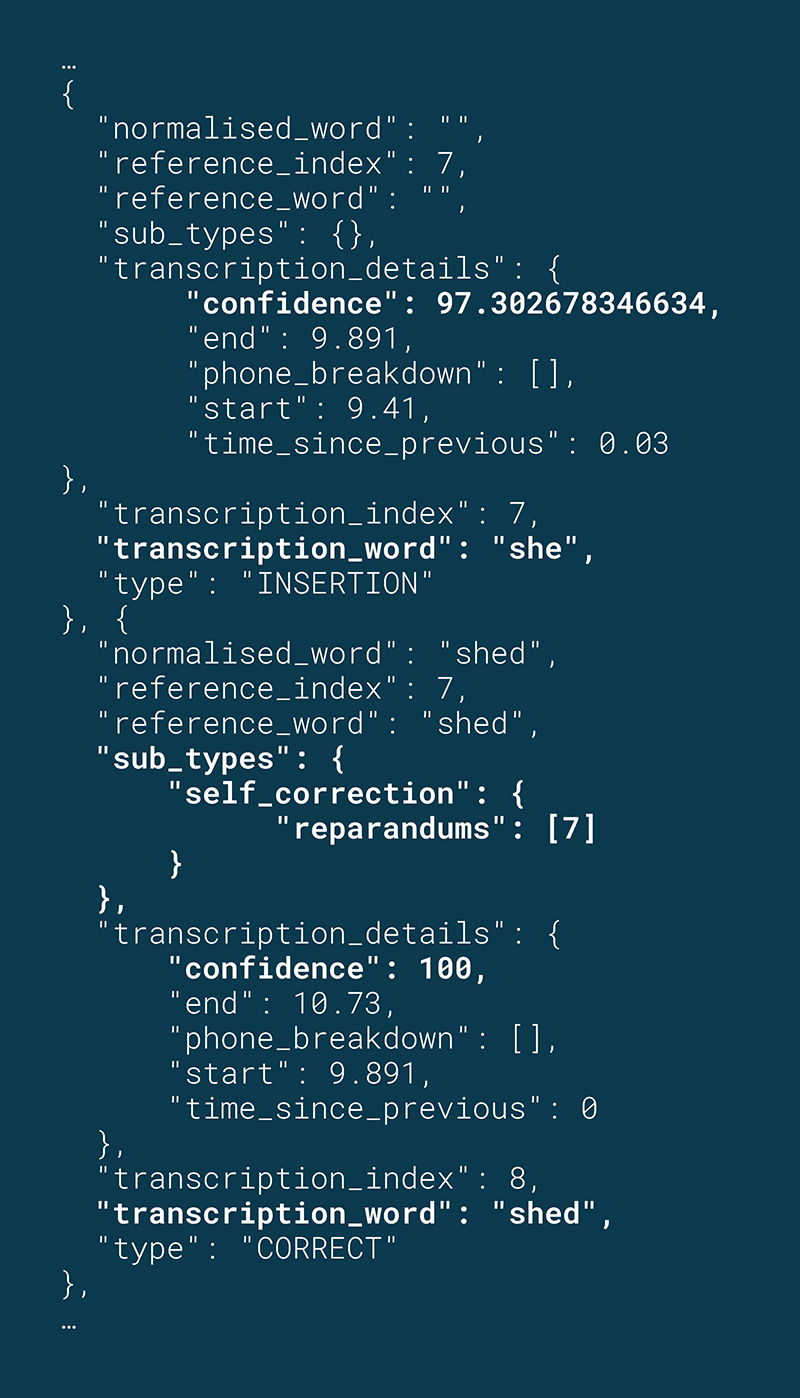
In a passage, a student reads the word shed as “she.” They then self-correct to “shed.”

JSON excerpt:
3. Incorrect tense
Our voice engine can also flag as a self-correction when the child has said the wrong tense of a verb (e.g., “walk” vs. “walked” vs. “walking”).
Example:
In a passage, a student reads the word bounding instead of “bounded.” They then self-correct to “bounded.”

JSON excerpt:

To summarize
At SoapBox, we’re committed to building a voice engine that is as — or more — accurate than human assessors; that understands kids of all ages, accents, and dialects; and that meets the needs of learning providers, educators, and students. Here’s what that means:
For learning and assessment providers
SoapBox now provides an additional data point that enables you to identify the three most common instances of oral reading fluency self-corrections and to surface self-correction metrics to teachers in a quick, easy, and digestible way.
As a SoapBox client observed in our research into self-corrections:
“For us, the self-correction feature further improves scoring accuracy by distinguishing how early readers approach a word to get to the correct word reading versus an actual incorrect reading. And higher scoring accuracy provides more opportunities for automatic speech recognition in higher stake assessment use cases, which we are exploring for the future.”
For educators
With a self-corrections metric, educators will have another important and actionable data point to help them monitor and track students’ fluent reading progress, personalize instruction, and offer intervention when needed.
For students
Automating the analysis and feedback of reading errors gives students the opportunity to practice independently and assess themselves more regularly.
Want to learn more about our voice engine?
If you’re ready to voice-power your oral reading assessments or other education tools, we’re here to help.
Share your use case on our Get Started form and a member of our team will be in touch to discuss it further with you and explain how we can help.
